

From the early days of mainframes, we’ve invested a lot of time and effort into thinking about how we use data in our computer systems, and in particular how we can structure that data to maximise efficiency and maintainability. From the early days of Cobol’s ISAM files to contemporary SQL databases, we’re used to optimising the way we handle data to ensure that our coded applications work well – a process in the relational database space we call normalisation. At scale, we move databases into data warehouses by extracting, transforming and loading (ETL) the various data items into an integrated, well-structured and high quality form typically using either a star or snowflake schema to support business analysis. Snowflake is now a term synonymous with data warehousing in the cloud. Developing an information architecture in this scenario is relatively straightforward.
The emergence of no-SQL databases saw the focus on data management shift to performance and scalability through a denormalization process where related data was embedded together. Enterprises now often have their business data stored across many disparate SQL and No-SQL databases. Data warehousing too has evolved, with data lakes becoming a new way of storing vast amounts of structured, semi-structured and unstructured data at a range of different levels of data quality. Data lakes use big data techniques for processing rather than relying on ETL-driven schemas. Defining the information architecture for data lakes becomes more complex, involving a storage layer for raw data, a processing layer for transformation, a metadata layer for cataloguing, and layers for security and governance to ensure data quality and compliance.
The recent emergence of AI into the consumer, business, and government space has introduced not just new demands on access to data, but a whole new industry around data science in order to build AI models that can reason using plain language. As architects we’ll leave the data science to the data scientists, but we still must ensure that whatever emerges from the data science team is properly architected and aligned with business requirements in order to contribute value to the business. AI introduces new architectural requirements we need to include for development of training data, development of inference data, and data maintenance.
Neither the data warehouse nor the data lake architecture on their own provide the flexibility to support the requirements of AI1. However, in 2021 a new approach emerged which combines data warehouses and data lakes into a construct known as a data lakehouse, a hybrid construct which addresses the problem of reconciling accurate analysis and processing of data with the sheer size of data lakes. Data lakehouses incorporate transactions with the four properties of Atomicity, Consistency, Isolation, and Durability – ACID transactions – to ensure database integrity. Data lakehouses also deliver scalable handling of metadata and the unification of batch and streaming data processing and a unified catalog to support data discovery and provenance. Data lakehouses have been shown to contribute to the creation of more reliable and consistent datasets, to reduce data duplication and latency, and to eliminate redundant ETL pipelines when used to support AI model training.
From a standard architecture perspective, the data lakehouse exists as a form of data asset, which in a standard architecture would be transformed to information, up to knowledge in the conceptual layer, and wisdom to make business decisions in the contextual layer. With AI in the picture, the data assets are transformed through the training process into the AI model which is then introduced as part of the infrastructure in the physical and component layers. In the basic AI capability, the data is transformed into knowledge which is spread throughout the many billions of AI model parameters and exists at the conceptual layer. In the more sophisticated reasoning models, the data is transformed through knowledge and into wisdom to make contextually-relevant autonomous business decisions. This is shown below.

Data Governance is the strategic activity which creates and enforces the policies, standards, compliance and accountability for data to ensure its quality, usability, integrity, and security.
Data Enablement is the strategic activity which makes organizational data accessible and visible across the business by breaking down data silos and creating an environment where data is easily collected. For the effective use of a data lakehouse we need to have three additional capabilities: Data and AI Management; Data and AI Security; and Data Quality. The AI Management System is well articulated in ISO 42001: AI Management System, and there is a growing number of ISO standards in the 8000 series related to data management and quality. AI security is as yet unwritten. We can build an overall architectural view of AI data as shown below.
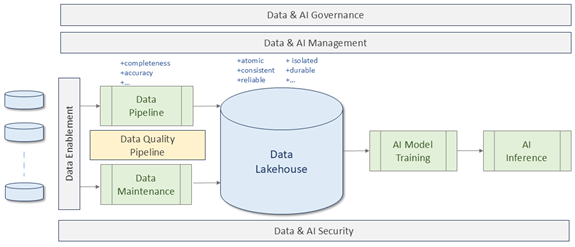
Regardless of whether we’re building a dataset to train a model or one to augment an already trained model, we need to send the raw data through the Data Quality pipeline to undergo ETL and then storage. This pipeline is also sometimes called the data wrangling or data cleansing pipeline. The capabilities applied in the course of transiting the pipeline, shown below, deliver a number of quality attributes such as completeness, accuracy, reliability and so on.

With the overall architecture of the AI data flow, and the decomposition into the data quality pipeline, we’ve got a solid foundation for our AI and AI Information architecture.
1William E,Data Lakehouse Architectures for Scalable AI Workloads, DeltaQ Technologies